



.jpg)

.png)
%20(1).png)
%20(700%20%C3%97%20500%20px)%20(2).png)



%20(1).png)
April 13, 2016
Data Science – more than just analysis
Data science has emerged as one of the hottest professions and academic disciplines of recent years, with demand for data scientists racing ahead of supply. But what is data science, what techniques are used, and how might data science be useful in different scenarios?
Data science focuses on extracting knowledge or insights from structured or unstructured data by adopting techniques and theories from mathematics, statistics, information science and computer science. It can bring new perspectives to data.
The decreasing cost of storage devices has led to an exceptional growth in data volumes. Large datasets are generated at an incredibly high speed and in various formats. Data science is equipped with all the necessary technologies needed to extract meaningful insights from this data - from predictive or prescriptive models to discovering hidden patterns in data.
Data Science vs data analysis
Data analysis is not new - people have been using statistics and related techniques to analyse data for some time. The main difference between data analysis and data science is explanation versus prediction.
Data analysis deals with explaining a phenomenon by extracting interesting patterns from individual data sets using well formatted queries.Data science, on the other hand, aims to discover and extract knowledge that can be used to make decisions and predictions, not just to explain what’s going on. Figure 1 shows the process that is usually adopted for a typical data science activity. The entire process usually needs domain knowledge, mathematics, statistics, software development and machine learning skills.

The modelling stage in this figure relates to creating predictive models which are used for performing predictive analytics.
Predictive Analytics
Predictive analytics deals with extracting meaningful information from data using data mining, statistical modelling and machine learning techniques. This information is used to predict unobserved/unknown patterns in the past, present or future. Instead of providing insight about why a particular event happened it focuses on providing foresight about when a particular event will happen. A predictive model is usually a mathematical equation representing relationships between various variables that contributed towards a specific outcome. One example of a predictive model would be a customer churn model, which identifies factors that contribute towards customer turnover.
In an analytics maturity model (Figure 2) predictive analytics is the third level in the curve. As we go higher and towards the right, the customer value increases with increased sophistication in techniques.

Stages of predictive analytics
The stages involved in predictive analytics are shown in Figure 3. It starts from defining a clear question and objective of the activity. Data cleaning, merging and quality assurance are done at the data preparation stage. Modelling is the process of actually creating a predictive model. It also involve verifying and testing the model results. A model can be deployed on a cloud as a web service. It is also very important to continuously update the model according to latest data.

The methods used for predictive modelling can be broadly grouped into regression and machine learning based approaches.
Methods of predictive modelling
Regression based techniques
Regression analysis is a technique used in statistical modelling which deals with estimating the relationship among variables. These techniques focus on representing interaction between different variables in the form of a mathematical model.

The above equation represents a simple linear regression model for data points. The equation contains one independent variable (predictor): , one dependent variable (prediction or response), , and two parameters, (intercept) and (co-efficient), and is an error term.
Let us take an example dataset containing heights and weights of university students. We want to find out whether there is any relationship between these two variables. Doing simple linear regression reveals that there is indeed: height and weight are directly proportional to each other. In order to determine whether this relationship is statistically significant or not we look at -value. For this relationship we get a -value of 0.0187 at a confidence level of 0.05 i.e. there is less than two percent chance of observing this relationship by chance.
Table 1: University students' height and weight data set
Figure 4: Regression line for university students' height and weight data set
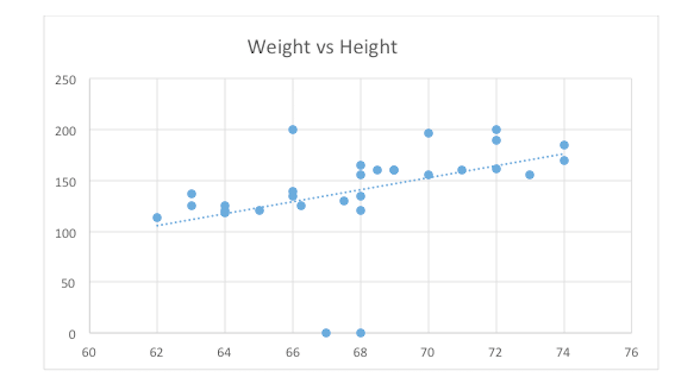
Table 2: University students' height and weight labelled data set
The other variations of regression analysis include:
Machine Learning Techniques
In cases where the underlying relationships between variables is very complex and it is hard to build a mathematical model to represent these relationships, machine learning techniques are used. These techniques learn from a training data set and encode relationships among attributes of a data set (Table 1).
Classification is another approach used for predictive analytics using machine learning techniques. Classification deals with automatically labelling data points into various categories. For training a classification model a labelled data set (Table 3) is used instead. The last column for this table contains the label assigned to each data point. A model can be tested once training is completed. For the testing stage a new data point (e.g. X [64,145]) is automatically assigned label A as shown in Figure 5.

Machine learning techniques include:
Once a predictive model is built it is important to quantify its performance. Table 3 depicts the approaches commonly used to assess the performance of a predictive model.
Table 3: Performance measures for a predictive model

Sample business cases for predictive analytics

Health Care: Identify prevalence of particular disease to a patient based health conditions.

Renewable energy: Energy forecasting, electricity price forecasting, predictive maintenance, operational cost minimisation.

Supply Chain: Simulate and optimise supply chain flows to reduce inventory.

Fraud and Crime Detection: Detect fraud, criminal activity, insurance claims, and tax evasion and credit card frauds.

Pricing: Identify the optimal price which will increase net profit.

Best employee selection for particular tasks at optimal compensation. Employee churn retention.
Prescriptive analytics
Prescriptive analytics is the final stage of the maturity of analytics curve shown in Figure 2. Once we know what will happen using predictive analytics, it is important to know the right course of action in the light of these predictions.

Figure 6: Prescriptive analytics uses hybrid data sources to predict, prescribe and adapt (Modaniel, n.d.)
For a football game planning software, prescriptive analytics can be used to answer following questions:
- When is it most likely that a particular player will be injured? And who could be the best replacement?
- When and how does the opponent have the best chance of scoring a goal? What strategy we should use for deciding players’ locations?
- How does the selection of a particular player affects success rate?

Figure 7: A football planning software
Conclusion
Data science has opened new avenues for analysing data. Its tools and techniques extend beyond traditional BI to show us insights never known before. Technologies like predictive and prescriptive analytics are capable of changing the way we understand our business and can help us make smarter decisions.